Berlioz Monitoring
Solution d'Observabilité Full-Stack pour Microservices
Plateforme complète d'observabilité temps réel combinant capture automatique d'erreurs Python, stockage structuré, diffusion WebSocket, analyse IA avec Claude (Bedrock) et dashboard Next.js 15 pour le diagnostic et l'analyse des microservices.
Berlioz Monitoring est une solution d'observabilité full-stack développée pour suivre, diagnostiquer et analyser en temps réel les erreurs des microservices Python. Elle combine instrumentation backend, persistance PostgreSQL, streaming temps réel via WebSocket, et analyse intelligente via IA pour contextualiser et résoudre rapidement les problèmes.
Fonctionnalités Principales
Monitoring Temps Réel
Flux live des erreurs de microservices avec mise à jour instantanée via WebSocket. Vue globale paginée de tous les logs avec tri et filtrage par date, type, statut, microservice et gravité.
Analytics & Métriques
Indicateurs de santé du système : nombre total d'erreurs, top microservices affectés, top types d'exceptions, distribution des codes HTTP, tendances temporelles avec détection automatique d'anomalies statistiques.
Analyse IA Intégrée
Génération automatique d'analyses IA via Claude (Bedrock) avec streaming SSE temps réel. Classification des erreurs (type Python, catégorie fonctionnelle, niveau de sévérité) et analyse de cause racine (RCA) basée sur stack trace et variables locales.
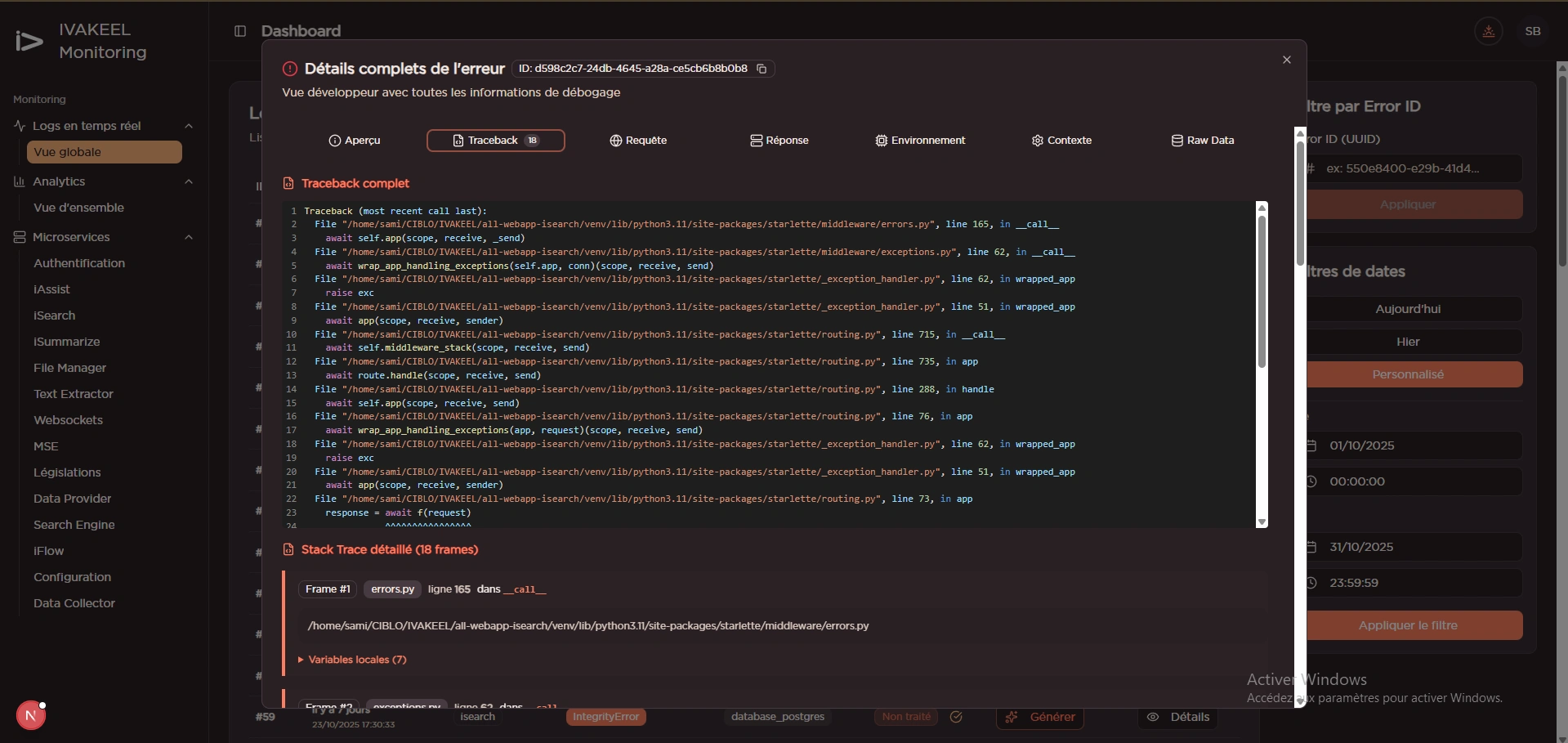
Debugging Avancé
Visualisation complète des stack traces Python (jusqu'à 18 frames), inspection des variables locales, contexte d'environnement (middleware, scope, sender), et catégorisation automatique des erreurs (IntegrityError, ImportError, etc.).
Filtres & Recherche
Système de filtrage avancé par date, microservice, type d'erreur, statut (traité/non traité), gravité. Recherche textuelle dans les logs et stack traces pour localiser rapidement les problèmes spécifiques.
Gestion Microservices
Liste complète des microservices (iSearch, iAssist, iSummarize, File Manager, etc.) avec analyse indépendante : taux d'erreurs, gravité moyenne, fréquence, tendances par service.
Notifications & Alertes
Système d'alertes automatiques via Email et Slack pour événements critiques. Détection d'anomalies statistiques (ex. +900% d'erreurs) avec notifications en temps réel pour triage immédiat.
Thèmes Visuels
Support dark/light mode avec adaptation dynamique des couleurs de graphiques et contrastes. Thème sombre professionnel (palette ambrée/orangée) et thème clair épuré pour une expérience visuelle optimale.
Aperçu de l'Interface

Voir

Voir

Voir

Voir

Voir
Architecture Technique
Modules Détaillés
📋Gestion des Logs
Ingestion unifiée via Celery/Redis avec payloads structurés et UUID d'erreur. API de logs persistants avec pagination, recherche texte et filtres avancés. Vue détaillée avec stack trace complète et variables locales.
📊Dashboard Admin
Tableau de bord centralisé avec vue globale des logs, graphiques d'analytics interactifs (histogrammes, camemberts, barres), indicateurs de tendance et métriques de santé système en temps réel.
🔧Vue Microservices
Analyse indépendante par microservice : taux d'erreurs, distribution des types d'exceptions, évolution temporelle, identification des services les plus critiques pour priorisation des interventions.
🧠Insights IA
Génération automatique d'analyses IA avec streaming SSE directement dans modale. Résumé exécutif, catégorisation (database, HTTP, validation, test), niveau de sévérité (faible, modéré, critique) et recommandations.
👥Interface Agent Support
Fusion des logs console, captures d'écran et logs backend pour diagnostic complet. Guidage utilisateur ou création automatique de tickets en cas d'erreur grave pour workflow de support optimisé.
🔔Système de Notifications
Alertes Email et Slack configurables pour événements critiques. Détection automatique d'anomalies statistiques avec seuils personnalisables. Notifications en temps réel pour triage immédiat.
Objectifs Stratégiques
Détecter et diagnostiquer rapidement les erreurs des microservices Python via observabilité temps réel et analyse automatique
Contextualiser les erreurs grâce à l'IA pour comprendre la cause racine et accélérer la résolution
Fournir une vue centralisée de la santé système avec analytics avancés et détection d'anomalies
Faciliter le triage et la priorisation des erreurs via classification intelligente et notifications proactives
Scalabiliser l'observabilité pour écosystèmes microservices complexes avec architecture distribuée haute performance